Download a Printable PDF of this Cheat Sheet. With this, we come to an end of Python Data Structures Basic Cheat sheet. To get in-depth knowledge, check out our Python Training here, that comes with 24.7 support to guide you throughout your learning period. Intellipaat’s Python course will let you master the concepts of widely-used and powerful programming language Python. Essential Basic Functionality is also from the pandas documentation and is a thorough overview of the essential functionality of pandas data structures. The paper pandas: a Foundational Python Library for Data Analysis and Statistics by Wes McKinney is a great overview of the package. Python Pandas Tutorial: A Complete Introduction for.
Decision tree is an algorithm which is mainly applied to data classification scenarios. It is a tree structure where each node represents the features and each edge represents the decision taken. Starting from the root node we go on evaluating the features for classification and take a decision to follow a specific edge. Whenever a new data point comes in, this same method is applied again and again and then the final conclusion is taken when all the required features are studied or applied to the classification scenario. So Decision tree algorithm is a supervised learning model used in predicting a dependent variable with a series of training variables. ExampleWe will take the drug test data available at kaggle.
As a first step we will read the data from a csv file using pandas and see it content and structure. Import pandas as pddatainput = pd.readcsv('drug.csv', delimiter=',') #the above code gives us the following result: Age Sex BP Cholesterol NatoK Drug0 23 F HIGH HIGH 25.355 drugY1 47 M LOW HIGH 13.093 drugC2 47 M LOW HIGH 10.114 drugC3 28 F NORMAL HIGH 7.798 drugX4 61 F LOW HIGH 18.043 drugY.195 56 F LOW HIGH 11.567 drugC196 16 M LOW HIGH 12.006 drugC197 52 M NORMAL HIGH 9.894 drugX200 rows x 6 columnsPre-processing the dataIn the next step we pre-process the above data to get numeric values for different text values we have in the data. That is useful to train and test the sample data about the decision to use certain drug for a given value of age, sex, BP etc.
As a marketing manager, you want a set of customers who are most likely to purchase your product. This is how you can save your marketing budget by finding your audience. As a loan manager, you need to identify risky loan applications to achieve a lower loan default rate. This process of classifying customers into a group of potential and non-potential customers or safe or risky loan applications is known as a classification problem.
Classification is a two-step process, learning step and prediction step. In the learning step, the model is developed based on given training data.
In the prediction step, the model is used to predict the response for given data. Decision Tree is one of the easiest and popular classification algorithms to understand and interpret.
It can be utilized for both classification and regression kind of problem.In this tutorial, you are going to cover the following topics:. Decision Tree Algorithm.
How does the Decision Tree algorithm work?. Attribute Selection Measures. Information Gain. Gain Ratio.
Gini index. Optimizing Decision Tree Performance. Classifier Building in Scikit-learn. Pros and Cons.
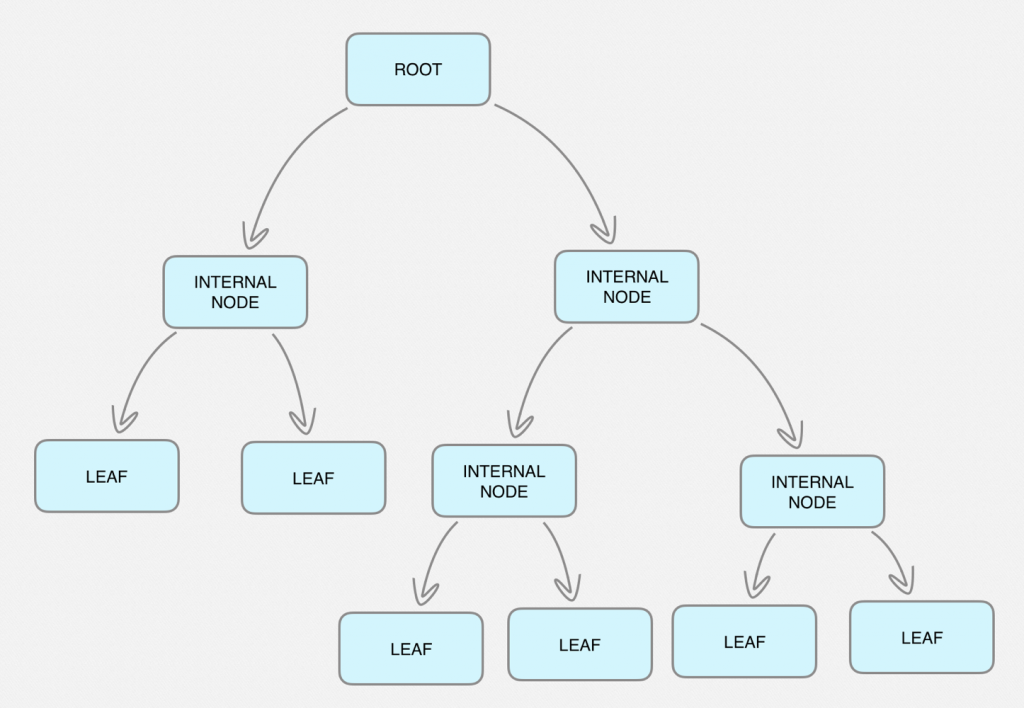
ConclusionDecision Tree AlgorithmA decision tree is a flowchart-like tree structure where an internal node represents feature(or attribute), the branch represents a decision rule, and each leaf node represents the outcome. The topmost node in a decision tree is known as the root node. It learns to partition on the basis of the attribute value. It partitions the tree in recursively manner call recursive partitioning. This flowchart-like structure helps you in decision making.
It's visualization like a flowchart diagram which easily mimics the human level thinking. That is why decision trees are easy to understand and interpret.Decision Tree is a white box type of ML algorithm. It shares internal decision-making logic, which is not available in the black box type of algorithms such as Neural Network. Its training time is faster compared to the neural network algorithm. The time complexity of decision trees is a function of the number of records and number of attributes in the given data. The decision tree is a distribution-free or non-parametric method, which does not depend upon probability distribution assumptions.
Decision trees can handle high dimensional data with good accuracy. Pregnantglucosebpskininsulinbmipedigreeagelabel0094516831Feature SelectionHere, you need to divide given columns into two types of variables dependent(or target variable) and independent variable(or feature variables).
#split dataset in features and target variablefeaturecols = 'pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree'X = pimafeaturecols # Featuresy = pima.label # Target variableSplitting DataTo understand model performance, dividing the dataset into a training set and a test set is a good strategy.Let's split the dataset by using function traintestsplit. You need to pass 3 parameters features, target, and testset size.
# Split dataset into training set and test setXtrain, Xtest, ytrain, ytest = traintestsplit(X, y, testsize=0.3, randomstate=1) # 70% training and 30% testBuilding Decision Tree ModelLet's create a Decision Tree Model using Scikit-learn. # Create Decision Tree classifer objectclf = DecisionTreeClassifier# Train Decision Tree Classiferclf = clf.fit(Xtrain,ytrain)#Predict the response for test datasetypred = clf.predict(Xtest)Evaluating ModelLet's estimate, how accurately the classifier or model can predict the type of cultivars.Accuracy can be computed by comparing actual test set values and predicted values. # Model Accuracy, how often is the classifier correct?print('Accuracy:',metrics.accuracyscore(ytest, ypred))Accuracy: 0.246753Well, you got a classification rate of 67.53%, considered as good accuracy. You can improve this accuracy by tuning the parameters in the Decision Tree Algorithm. Visualizing Decision TreesYou can use Scikit-learn's exportgraphviz function for display the tree within a Jupyter notebook. For plotting tree, you also need to install graphviz and pydotplus.pip install graphvizpip install pydotplusexportgraphviz function converts decision tree classifier into dot file and pydotplus convert this dot file to png or displayable form on Jupyter.
From sklearn.tree import exportgraphvizfrom sklearn.externals.six import StringIOfrom IPython.display import Imageimport pydotplusdotdata = StringIOexportgraphviz(clf, outfile=dotdata,filled=True, rounded=True,specialcharacters=True,featurenames = featurecols,classnames='0','1')graph = pydotplus.graphfromdotdata(dotdata.getvalue)graph.writepng('diabetes.png')Image(graph.createpng)In the decision tree chart, each internal node has a decision rule that splits the data. Gini referred as Gini ratio, which measures the impurity of the node. You can say a node is pure when all of its records belong to the same class, such nodes known as the leaf node.Here, the resultant tree is unpruned. This unpruned tree is unexplainable and not easy to understand. In the next section, let's optimize it by pruning.
Optimizing Decision Tree Performance.criterion: optional (default=”gini”) or Choose attribute selection measure: This parameter allows us to use the different-different attribute selection measure. Supported criteria are “gini” for the Gini index and “entropy” for the information gain.splitter: string, optional (default=”best”) or Split Strategy: This parameter allows us to choose the split strategy. Supported strategies are “best” to choose the best split and “random” to choose the best random split.maxdepth: int or None, optional (default=None) or Maximum Depth of a Tree: The maximum depth of the tree.
Msi n1996 ethernet driver free download - Network:3C905C-TXM Ethernet Adaptor Driver, MSI nVidia-based Graphics Drivers (Windows 2000/XP), Realtek RTL Gigabit and Fast Ethernet NIC Driver (Windows. N1996 network drivers for mac windows 10.
If None, then nodes are expanded until all the leaves contain less than minsamplessplit samples. The higher value of maximum depth causes overfitting, and a lower value causes underfitting.In Scikit-learn, optimization of decision tree classifier performed by only pre-pruning. Maximum depth of the tree can be used as a control variable for pre-pruning. In the following the example, you can plot a decision tree on the same data with maxdepth=3. Other than pre-pruning parameters, You can also try other attribute selection measure such as entropy. # Create Decision Tree classifer objectclf = DecisionTreeClassifier(criterion='entropy', maxdepth=3)# Train Decision Tree Classiferclf = clf.fit(Xtrain,ytrain)#Predict the response for test datasetypred = clf.predict(Xtest)# Model Accuracy, how often is the classifier correct?print('Accuracy:',metrics.accuracyscore(ytest, ypred))Accuracy: 0.627706Well, the classification rate increased to 77.05%, which is better accuracy than the previous model.
Visualizing Decision Trees from sklearn.externals.six import StringIOfrom IPython.display import Imagefrom sklearn.tree import exportgraphvizimport pydotplusdotdata = StringIOexportgraphviz(clf, outfile=dotdata,filled=True, rounded=True,specialcharacters=True, featurenames = featurecols,classnames='0','1')graph = pydotplus.graphfromdotdata(dotdata.getvalue)graph.writepng('diabetes.png')Image(graph.createpng)This pruned model is less complex, explainable, and easy to understand than the previous decision tree model plot. Pros. Decision trees are easy to interpret and visualize.

It can easily capture Non-linear patterns. It requires fewer data preprocessing from the user, for example, there is no need to normalize columns. It can be used for feature engineering such as predicting missing values, suitable for variable selection. The decision tree has no assumptions about distribution because of the non-parametric nature of the algorithm.Cons. Sensitive to noisy data. It can overfit noisy data.
The small variation(or variance) in data can result in the different decision tree. This can be reduced by bagging and boosting algorithms. Decision trees are biased with imbalance dataset, so it is recommended that balance out the dataset before creating the decision tree.ConclusionCongratulations, you have made it to the end of this tutorial!In this tutorial, you covered a lot of details about Decision Tree; It's working, attribute selection measures such as Information Gain, Gain Ratio, and Gini Index, decision tree model building, visualization and evaluation on diabetes dataset using Python Scikit-learn package. Also, discussed its pros, cons, and optimizing Decision Tree performance using parameter tuning.Hopefully, you can now utilize the Decision tree algorithm to analyze your own datasets.If you want to learn more about Machine Learning in Python, take DataCamp's course.